https://magazine.sebastianraschka.com/p/from-gpt-2-to-gpt-oss-analyzing-the 글 번역했습니다.
OpenAI는 이번 주에 2019년 GPT-2 이후 첫 번째 오픈 웨이트 모델인 gpt-oss-120b와 gpt-oss-20b라는 새로운 오픈 웨이트 LLM을 출시했습니다. 그리고 몇 가지 영리한 최적화 덕분에 로컬에서 실행할 수 있습니다(자세한 내용은 나중에 설명합니다).
OpenAI가 완전 개방형 대형 모델을 공개한 것은 GPT-2 이후 이번이 처음입니다. 이전 GPT 모델은 트랜스포머 아키텍처가 어떻게 확장되는지를 보여주었습니다. 그 후 2022년 ChatGPT 릴리스는 글쓰기 및 지식(그리고 이후 코딩) 작업에 대한 구체적인 유용성을 입증함으로써 이러한 모델을 주류로 만들었습니다. 이제 오랫동안 기다려온 가중치 모델을 공유하게 되었으며, 이 아키텍처에는 몇 가지 흥미로운 세부 사항이 포함되어 있습니다.
저는 지난 며칠 동안 코드와 기술 보고서를 읽으며 가장 흥미로운 세부 사항을 요약했습니다. (며칠 후 OpenAI는 GPT-5도 발표했는데, 이 글의 마지막 부분에서 gpt-oss 모델의 맥락에서 간략히 설명하겠습니다.)
아래는 이 문서에서 다루는 내용을 간략하게 미리 살펴본 것입니다. 보다 쉽게 탐색하려면 문서 페이지 왼쪽에 있는 목차를 사용하는 것이 좋습니다.
- GPT-2와 모델 아키텍처 비교
- 단일 GPU에 gpt-oss 모델을 맞추기 위한 MXFP4 최적화
- 너비 대 깊이 트레이드 오프(gpt-oss vs Qwen3)
- 주의 편향 및 싱크
- GPT-5와의 벤치마크 및 비교
1. 모델 아키텍처 개요
아키텍처에 대해 더 자세히 설명하기 전에 아래 그림 1에 표시된 두 가지 모델인 gpt-oss-20b와 gpt-oss-120b에 대한 개요부터 살펴보겠습니다.

이전에 최근의 LLM 아키텍처 다이어그램을 보셨거나 이전에 제가 작성한대규모 아키텍처 비교기사를 보면 언뜻 보기에 새롭거나 특이한 점이 없다는 것을 알 수 있습니다.
주요 LLM 개발자들은 동일한 기본 아키텍처를 사용한 다음 약간의 조정을 적용하는 경향이 있기 때문에 이는 놀라운 일이 아닙니다. 이것은 순전히 제 추측이지만, 다음과 같은 이유 때문이라고 생각합니다.
- 이 연구실들 사이에는 상당한 직원 순환이 이루어집니다.
- 아직 트랜스포머 아키텍처보다 더 나은 것을 찾지 못했습니다. 상태 공간 모델과 텍스트 확산 모델이 존재하지만, 제가 아는 한 이 정도 규모에서 트랜스포머만큼 성능이 좋다는 것을 보여준 사례는 없습니다. (제가 찾은 대부분의 비교는 벤치마크 성능에만 초점을 맞추고 있습니다. 이 모델이 실제 멀티턴 작성 및 코딩 작업을 얼마나 잘 처리하는지는 아직 명확하지 않습니다. 이 글을 쓰는 시점에서 가장 높은 순위를 차지한 비순수 트랜스포머 기반 모델은LM 아레나는 Transformer 상태 공간 모델 하이브리드인 잠바(96위)입니다).
- 대부분의 이득은 아키텍처의 대대적인 변경보다는 데이터와 알고리즘의 조정에서 비롯된 것일 가능성이 높습니다.
그렇긴 하지만, 디자인 선택에는 여전히 흥미로운 측면이 많이 있습니다. 일부는 위 그림에 표시되어 있지만 일부는 그렇지 않은 경우도 있지만 나중에 설명하겠습니다. 이 글의 나머지 부분에서는 이러한 기능을 강조하고 한 번에 하나씩 다른 아키텍처와 비교하겠습니다.
또한 저는 OpenAI와 어떠한 방식으로도 제휴 관계가 없음을 알려드립니다. 제 정보는 공개된 모델 코드를 검토하고 기술 보고서를 읽으면서 얻은 것입니다. 이러한 모델을 로컬에서 사용하는 방법을 배우고 싶다면 OpenAI의 공식 모델 허브 페이지에서 시작하는 것이 가장 좋습니다.
20B 모델은 최대 16GB RAM이 장착된 일반 사용자용 GPU에서 실행할 수 있습니다. 120B 모델은 80GB RAM 또는 최신 하드웨어가 장착된 단일 H100에서 실행할 수 있습니다. 몇 가지 중요한 주의 사항이 있으므로 나중에 다시 설명하겠습니다.
2. GPT-2에서 제공
gpt-oss와 최신 아키텍처를 비교하기 전에 타임머신에 탑승하여 GPT-2(그림 2)를 나란히 살펴봄으로써 얼마나 발전했는지 확인해 보겠습니다.

gpt-oss와 GPT-2는 모두 트랜스포머 아키텍처를 기반으로 구축된 디코더 전용 LLM입니다.주의는 필요해 (2017)종이. 수년에 걸쳐 많은 세부 사항이 발전했습니다.
그러나 이러한 변화는 gpt-oss에만 국한된 것이 아닙니다. 나중에 살펴보겠지만, 이러한 변화는 다른 많은 LLM에서도 나타납니다. 이전 글에서 이러한 측면 중 많은 부분을 설명했기 때문에대규모 아키텍처 비교기사에서는 각 하위 섹션을 간결하고 집중적으로 설명하려고 노력하겠습니다.
1.1 드롭아웃 제거하기
드롭아웃 (2012)은 훈련 중에 레이어 활성화 또는 주의 점수(그림 3)의 일부를 무작위로 "드롭아웃"(즉, 0으로 설정)하여 과적합을 방지하는 전통적인 기법입니다. 그러나 최신 LLM에서는 드롭아웃이 거의 사용되지 않으며, GPT-2 이후 대부분의 모델에서는 드롭아웃이 사라졌습니다(말장난 의도는 없습니다).

드롭아웃은 원래 트랜스포머 아키텍처에서 상속되었기 때문에 GPT-2에서 원래 사용되었다고 생각합니다. 연구원들은 드롭아웃이 LLM 성능을 실제로 향상시키지 못한다는 것을 알아차렸을 것입니다(저도 소규모 GPT-2 복제 실행에서 동일한 결과를 확인했습니다). 이는 LLM이 일반적으로 대규모 데이터 세트에 대해 단일 에포크에 대해서만 훈련되기 때문에 드롭아웃이 처음 도입된 수백 개의 에포크에 대한 훈련 체제와 대조적이기 때문일 수 있습니다. 따라서 LLM은 훈련 중에 각 토큰을 한 번만 보기 때문에 과적합의 위험이 거의 없습니다.
흥미롭게도 드롭아웃은 수년 동안 LLM 아키텍처 설계에서 무시되어 왔지만, 저는2025년 연구 논문소규모 LLM 실험(Pythia 1.4B)을 통해 드롭아웃이 이러한 단일 에포크 체제에서 다운스트림 성능을 저하시킨다는 사실을 확인했습니다.
1.2 절대적 위치 임베딩을 대체하는 RoPE
트랜스포머 기반 LLM에서는 주의 메커니즘으로 인해 위치 인코딩이 필요합니다. 기본적으로 주의는 입력 토큰을 순서가 없는 것처럼 취급합니다. 원래 GPT 아키텍처에서 절대 위치 임베딩은 시퀀스의 각 위치에 대해 학습된 임베딩 벡터를 추가한 다음 토큰 임베딩에 추가하는 방식으로 이 문제를 해결했습니다(그림 4).

RoPE (Rotary Position Embedding)는 위치 정보를 별도의 임베딩으로 추가하는 대신 각 토큰의 위치에 따라 쿼리와 키 벡터를 회전하는 방식으로 위치를 인코딩하는 다른 접근 방식을 도입했습니다. (RoPE는 우아한 아이디어이지만 설명하기에는 다소 까다로운 주제이기도 합니다. 언젠가 별도로 자세히 다룰 계획입니다.)
2021년에 처음 소개된 RoPE는 2023년 오리지널 라마 모델의 출시와 함께 널리 채택되었으며, 이후 최신 LLM의 필수 요소로 자리 잡았습니다.
1.3 Swish/SwiGLU 가 겔루를 대체합니다.
초기 GPT 아키텍처는 GELU를 사용했습니다. 왜 이제 GELU 대신 Swish를 사용하나요? Swish는 계산적으로 약간 더 저렴한 것으로 간주되며, 제 생각에는 그게 전부입니다. 어떤 논문을 보느냐에 따라 모델링 성능 측면에서 어느 쪽이 다른 쪽보다 약간 더 낫다는 것을 알 수 있습니다. 제 생각에는 이러한 작은 차이는 아마도 표준 오차 범위 내에 있으며, 하이퍼파라미터 민감도에 따라 마일리지가 달라질 수 있습니다.
활성화 함수는 10여 년 전 딥러닝 커뮤니티가 ReLU에 대체로 정착하기 전까지 뜨거운 논쟁의 대상이었습니다. 그 이후로 연구자들은 더 부드러운 곡선을 가진 ReLU와 유사한 여러 가지 변형을 제안하고 시도해 왔으며, 그 중 GELU와 Swish(그림 5)가 자리를 잡은 것입니다.

초기 GPT 아키텍처는 다음과 같이 정의되는 GELU를 사용했습니다.0.5x * [1 + erf(x / sqrt(2))]. 여기,erf(오류 함수의 줄임말)는 가우시안 적분이며 가우시안 적분의 다항식 근사를 사용하여 계산되므로 Swish에서 사용되는 시그모이드와 같은 단순한 함수보다 계산 비용이 더 많이 듭니다(여기서 Swish는 단순히x * sigmoid(x).
실제로 Swish는 GELU보다 계산적으로 약간 더 저렴하며, 이것이 대부분의 최신 모델에서 GELU를 대체한 주된 이유일 것입니다. 어떤 논문을 보느냐에 따라 모델링 성능 측면에서 어느 쪽이 다소 더 우수할 수도 있습니다. 하지만 이러한 이득은 표준 오차 범위 내에 있는 경우가 많으며, 승자는 하이퍼파라미터 튜닝에 크게 좌우될 것입니다.
Swish는 오늘날 대부분의 아키텍처에서 사용됩니다. 하지만 GELU가 완전히 잊혀진 것은 아니며, 예를 들어 Google의 Gemma 모델에서는 여전히 GELU를 사용하고 있습니다.
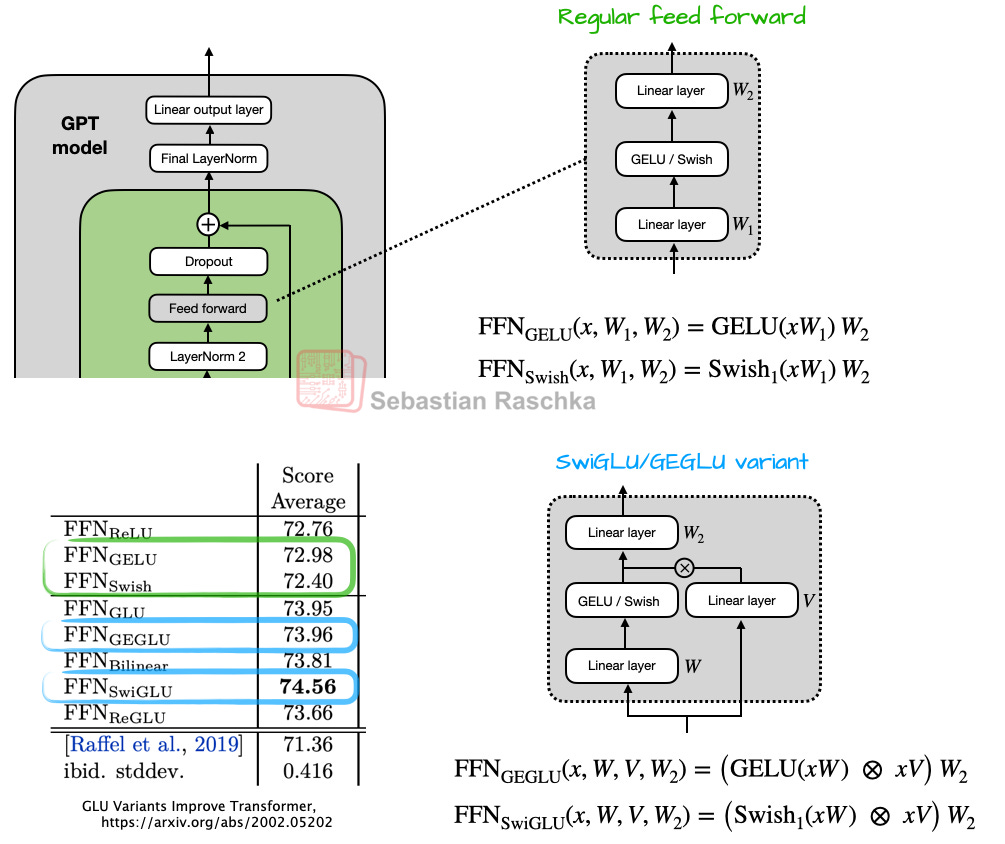
하지만 더 주목할 만한 점은 피드 포워드 모듈(소형 다층 퍼셉트론)이 게이트형 "GLU" 모듈로 대체되었다는 점인데, GLU는 게이트형 선형 유닛의 약자이며2020 논문. 구체적으로, 완전히 연결된 2개의 레이어는 아래 그림 6과 같이 완전히 연결된 3개의 레이어로 대체됩니다.

언뜻 보기에는 추가 레이어로 인해 단순히 더 많은 매개 변수가 있기 때문에 GEGLU/SwiGLU 변형이 일반 피드 포워드 레이어보다 더 나은 것처럼 보일 수 있습니다. 하지만 이는 속임수이며 실제로는W그리고V가중치 레이어는 일반적으로 각각 절반 크기로 선택됩니다.W_1레이어를 기존 피드 포워드 레이어에 추가합니다.
이를 더 잘 설명하기 위해 일반 변형과 GLU 변형의 구체적인 코드 구현을 고려해 보세요.

따라서 임베딩 차원이 1024라고 가정해 보겠습니다. 일반 피드 포워드의 경우, 이는 다음과 같습니다.
- FC1: 1024 × 4096 = 4,194,304
- FC2: 1024 × 4096 = 4,194,304
그것은 fc1 + fc2 = 8,388,608 개의 매개변수입니다.
GLU 변형의 경우
- FC1: 1024 × 2048 = 2,097,152
- fc2: 1024 × 2048 = 2,097,152
- FC3: 2048 × 1024 = 2,097,152
즉, 3 × 2,097,152 = 6,291,456개의 가중치 매개변수입니다.
따라서 전반적으로 GLU 변형을 사용하면 매개 변수가 더 적고 성능도 더 좋아집니다. 이렇게 성능이 더 좋은 이유는 이러한 GLU 변형이 추가적인 곱셈 상호 작용을 제공하여 표현력을 향상시키기 때문입니다(딥 뉴럴 네트워크가 얕고 넓은 뉴럴 네트워크보다 성능이 좋은 이유는 잘 훈련된 경우와 동일합니다).
1.4 전문가 혼합이 단일 피드포워드 모듈을 대체합니다.
이전 섹션에서 설명한 것처럼 피드 포워드 모듈을 SwiGLU로 업그레이드하는 것 외에도, gpt-oss는 각 토큰 생성 단계마다 하위 집합만 사용하여 단일 피드 포워드 모듈을 여러 피드 포워드 모듈로 대체합니다. 이 접근 방식을 전문가 혼합(MoE)이라고 하며 아래 그림 8에 설명되어 있습니다.

따라서단일피드 포워드 모듈을 사용하여여러피드 포워드 모듈을 사용하면 모델의 총 파라미터 수가 크게 증가합니다(MoE 설정에서와 같이). 하지만 핵심은 모든 토큰에 대해 모든 전문가를 사용("활성화")하지 않는다는 것입니다. 대신 라우터는 토큰당 소수의 전문가 하위 집합만 선택합니다.
한 번에 소수의 전문가만 활동하기 때문에 MoE 모듈은 종종 다음과 같이 불립니다.sparse와는 대조적으로밀도모듈은 항상 전체 파라미터 세트를 사용합니다. 그러나 MoE를 통한 총 파라미터 수가 많으면 LLM의 용량이 증가하므로 학습 중에 더 많은 지식을 차지할 수 있습니다.
하지만 모든 파라미터를 동시에 사용하지 않기 때문에 희소성은 추론의 효율성을 유지합니다.
(재미있는 사실: 대부분의 MoE 모델에서 전문가 가중치는 전체 모델 파라미터의 90% 이상을 차지합니다.)
1.5 그룹화된 쿼리 어텐션이 멀티-헤드 어텐션을 대체합니다.
이전 글에서 언급했듯이, 최근 몇 년 동안 그룹화된 쿼리 주의(GQA)가 멀티 헤드 주의(MHA)를 대체하는 컴퓨팅 및 매개변수 효율성이 더 높은 대안으로 부상하고 있습니다.
MHA에서는 각 헤드마다 고유한 키와 값 집합이 있습니다. GQA는 여러 헤드를 그룹화하여 동일한 키와 값 투영을 공유함으로써 메모리 사용량을 줄입니다.
예를 들어 그림 9와 같이 2개의 키-값 그룹과 4개의 주의 헤드가 있는 경우, 헤드 1과 2는 한 세트의 키와 값을 공유하고 헤드 3과 4는 다른 세트를 공유할 수 있습니다. 이러한 그룹화는 키 및 값 계산의 총 수를 줄여 메모리 사용량을 줄이고 효율성을 개선하며, 모델링 성능에는 눈에 띄는 영향을 미치지 않는다고 합니다.

따라서 GQA의 핵심 아이디어는 키와 값 헤드를 여러 쿼리 헤드에서 공유하여 키와 값 헤드의 수를 줄이는 것입니다. 이렇게 하면 (1) 모델의 매개변수 수가 줄어들고 (2) 추론 중에 키와 값 텐서를 저장하고 KV 캐시에서 검색해야 하는 키와 값의 수가 줄어들기 때문에 메모리 대역폭 사용량이 감소합니다.
(GQA가 코드에서 어떻게 보이는지 궁금하다면 내GPT-2에서 라마 3으로 변환 가이드KV 캐시가 없는 버전 및 내 KV 캐시 변형의 경우여기.)
GQA는 주로 MHA에 대한 계산 효율성 해결 방법이지만, 절제 연구(예를 들어원본 GQA 용지및라마 2 종이)에 따르면 LLM 모델링 성능 측면에서 표준 MHA와 비슷한 성능을 보입니다.
1.6 Sliding Window Attention
Sliding-window attention(아래 그림 10)은 처음에 LongFormer paper (2020) 그리고 나중에 미스트랄에 의해 대중화되었습니다. 흥미롭게도 gpt-oss는 이를 매 초 단위로 적용합니다. 멀티헤드 주의 또는 이 경우에는 그룹화된 쿼리 주의(GQA)의 변형으로 생각할 수 있는데, 주의 컨텍스트가 더 작은 창으로 제한되어 메모리 사용량과 컴퓨팅 비용을 모두 줄일 수 있습니다.

구체적으로, gpt-oss는 전체 컨텍스트를 고려하는 GQA 레이어와 128개 토큰으로 제한된 Sliding-window를 사용하는 GQA 레이어를 번갈아 가며 사용합니다.
에서 설명했듯이이전 기사, Gemma 2 (2024)비슷한 1:1 비율을 사용했습니다.Gemma 3올해 초에는 훨씬 더 나아가 5:1 비율로 전환하여 5개의 Sliding-window(로컬) 관심 레이어당 하나의 전체 관심 레이어만 표시하는 방식으로 변경했습니다.
Gemma ablation 연구에 따르면, 아래 그림과 같이 Sliding-window attention은 모델링 성능에 미치는 영향이 미미합니다. Gemma 2의 창 크기는 4096토큰이었지만 Gemma 3에서는 1024토큰으로 줄었습니다. gpt-oss에서는 창이 128토큰에 불과하여 현저히 작습니다.
재미있는 사실은공식 발표 기사에 따르면 Sliding-window attention은 GPT-3에서 이미 사용된 것으로 보입니다:
The models use alternating dense and locally banded sparse attention patterns, similar to GPT-3
정말 몰랐네요! 원본 GPT-3 논문을 다시 확인해봤더니, 실제로 거기에 언급되어 있었네요.
We use the same model and architecture as GPT-2 [ RWC+19 ], including the modified initialization, pre-normalization, and reversible tokenization described therein, with the exception that we use alternating dense and locally banded sparse attention patterns in the layers of the transformer, similar to the Sparse Transformer [ CGRS19 ].
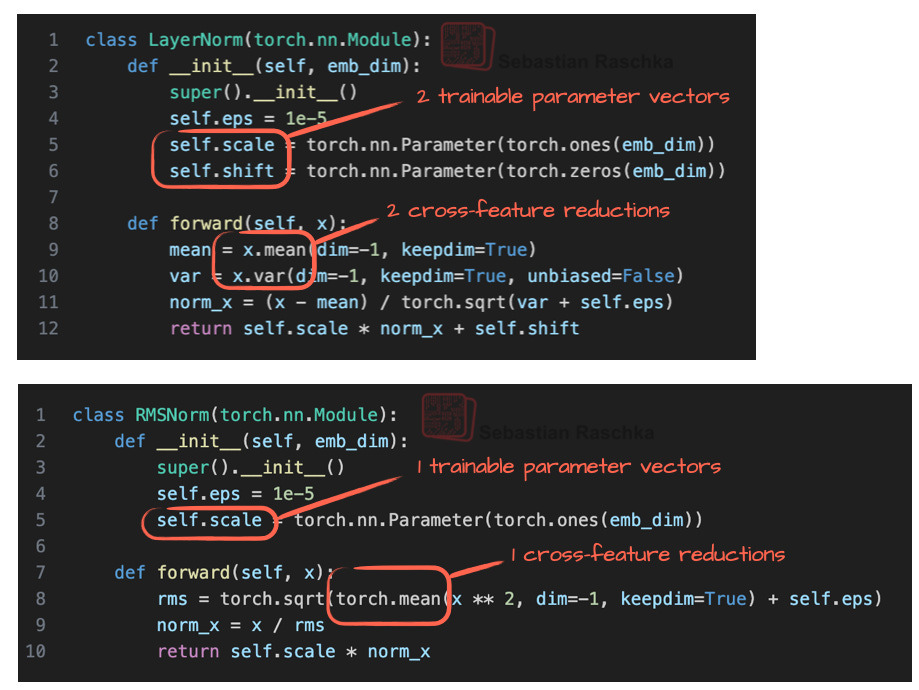
1.7 RMSNorm은 LayerNorm을 대체합니다
마지막으로, GPT-2에서 도입된 작은 개선 사항 중 하나는 LayerNorm (2016)을 RMSNorm (2019)로 대체하는 것입니다. 이는 최근 몇 년간 일반적인 트렌드가 되었습니다.
GELU를 Swish와 SwiGLU로 교체하는 것과 유사하게, RMSNorm은 작은 규모이지만 합리적인 효율성 개선 중 하나입니다. RMSNorm은 LayerNorm과 마찬가지로 레이어 활성화 값을 정규화하는 목적으로 사용되며, 아래 그림 11에 표시되어 있습니다.
최근까지 이 작업의 주요 선택지였던 BatchNorm은 효율적인 병렬화가 어렵고(평균과 분산 배치 통계 때문) 작은 배치 크기에서 성능이 저하되기 때문에 선호되지 않게 되었습니다.

위의 그림 11에서 볼 수 있듯이 LayerNorm과 RMSNorm은 모두 레이어 출력을 적절한 범위로 스케일링합니다.
레이어 출력의 평균과 단위 분산이 0(분산 1, 표준편차 1)이 되도록 평균을 빼고 표준편차로 나눕니다.
RMSNorm은 입력을 루트-평균-제곱으로 나눕니다. 평균과 단위 분산을 0으로 강제하지는 않지만 평균과 분산의 범위는 평균의 경우 -1에서 1, 분산의 경우 0에서 1로 적당한 범위입니다. 그림 11에 표시된 이 특정 예에서 평균은 0.77이고 분산은 0.41입니다.
LayerNorm과 RMSNorm 모두 활성화 스케일을 안정화하고 최적화를 개선하지만, 계산 비용이 더 저렴하기 때문에 대규모 LLM에서는 RMSNorm이 선호되는 경우가 많습니다. LayerNorm과 달리 RMSNorm은 편향(시프트) 항이 없으며 값비싼 평균 및 분산 계산을 단일 루트-평균 제곱 연산으로 줄입니다. 따라서 교차 기능 감소 횟수가 2개에서 1개로 줄어들어 GPU의 통신 오버헤드가 감소하고 학습 효율성이 향상됩니다.
그림 12는 이것이 코드에서 어떻게 보이는지 보여줍니다.
1.8 GPT-2 레거시
GPT-2로 시작하면 최신 아키텍처에서 볼 수 있는 추가 기능과 조정에 압도되지 않고 기본 사항(주의 메커니즘, 위치 임베딩, 정규화 및 전체 훈련 파이프라인)에 집중할 수 있습니다.
사실, 새로운 변경 사항을 적용하기 전에 먼저 GPT-2에 대해 배우고 구현해보는 것도 시간을 투자할 만한 가치가 있다고 생각합니다. 이러한 변경 사항을 더 쉽게 이해할 수 있을 뿐만 아니라 어떤 제한 사항이나 문제를 해결하려고 하는지 더 잘 이해할 수 있기 때문에 변경 사항을 더 높이 평가할 수 있을 것입니다.
예를 들어, 최근에 구현한 GPT-2 코드를 기반으로 Qwen3 아키텍처를 처음부터 구현했는데, 이 아키텍처는 gpt-oss와 매우 유사합니다. 이는 다음 주제로 이어집니다: gpt-oss와 최신 아키텍쳐(Qwen3) 비교.
3. gpt-oss와 최신 아키텍처(Qwen3) 비교
여기서 Qwen3를 선택한 이유는 이 글을 쓰는 시점을 기준으로 최고의 오픈 가중치 모델 중 하나이기 때문입니다. 또한 Qwen3 MoE 모델 중 하나는 학습 가능한 파라미터 측면에서 전체 크기가 비교적 비슷하기 때문에 GPT OSS와 어느 정도 직접적으로 비교할 수 있습니다.
아래 그림 13은 gpt-oss-20b를 비슷한 크기의 Qwen3 모델과 비교한 것입니다.

그림에서 볼 수 있듯이 gpt-oss 20B와 Qwen3 30B-A3B는 아키텍처 구성 요소가 매우 유사합니다. 치수를 제외하고 가장 큰 차이점은 1.6절의 앞부분에서 설명한 것처럼 gpt-oss는 Sliding-window attention(이 그림에는 표시되지 않음)를 사용하는 반면, Qwen3는 그렇지 않다는 점입니다.
다음 하위 섹션에서 주목할 만한 세부 사항을 하나씩 살펴보겠습니다.
3.1 너비 대 깊이

반면에 gpt-oss는 훨씬 더 광범위한 아키텍처입니다:
- 2048이 아닌 2880의 임베딩 크기
- 768이 아닌 5760의 중간 전문가(피드 포워드) 투영 차원
또한 gpt-oss는 주의 헤드를 두 배 더 많이 사용하지만 모델의 너비가 직접적으로 증가하지는 않는다는 점에 유의할 필요가 있습니다. 너비는 임베딩 치수에 의해 결정됩니다.
고정된 수의 파라미터가 주어졌을 때 어떤 접근 방식이 다른 접근 방식보다 유리할까요? 일반적으로 심층 모델은 더 많은 유연성을 제공하지만 폭발 및 사라지는 그라데이션으로 인한 불안정성 문제로 인해 훈련하기가 더 어려울 수 있습니다(RMSNorm 및 바로 가기 연결은 이를 완화하는 것을 목표로 합니다).
더 넓은 아키텍처는 더 높은 메모리 비용으로 더 나은 병렬화를 통해 추론 시 더 빠르다는 장점이 있습니다(초당 처리량이 더 높습니다).
모델링 성능과 관련하여, 안타깝게도 제가 알고 있는 좋은 사과 대 사과 비교(매개변수 크기와 데이터 세트가 일정하게 유지되는 경우)는Gemma 2 논문 (표 9)에 따르면 9B 매개변수 아키텍처의 경우 더 넓은 설정이 더 깊은 설정보다 약간 더 나은 것으로 나타났습니다. 4개의 벤치마크에서 더 넓은 모델의 평균 점수는 52.0점, 더 깊은 모델의 평균 점수는 50.8점이었습니다.
3.2 소수의 대형 전문가 대 다수의 소형 MoE
위 그림 14에서 볼 수 있듯이, gpt-oss는 예상외로 적은 수의 MoE(32명 대신 128명)를 보유하고 있으며, 토큰당 활성화된 Epxert도 8명 대신 4명만 사용합니다. 그러나 각 전문가는 Qwen3의 전문가보다 훨씬 더 큽니다.
이는 최근 트렌드와 발전 방향이 더 많은 소규모 모델이 유리하다는 점을 지적하고 있기 때문에 흥미로운 점입니다. 이 변화는 총 매개변수 크기가 일정할 때, DeepSeekMoE 논문의 아래 그림 15에서 잘 보여집니다.

특히 딥시크의 모델과 달리 gpt-oss나 Qwen3는 공유 전문가를 사용하지 않습니다.
공정하게 말하자면, gpt-oss의 전문가 수가 적다는 것은 20B 규모의 부작용일 수 있습니다. 아래 그림 16에서 볼 수 있듯이 아래 120B 모드를 보면 실제로 MoE(및 트랜스포머 블록)의 수를 늘리면서 다른 모든 요소는 고정된 상태로 유지했습니다.

20B와 120B 모델이 너무 비슷하다는 사실에 대한 지루한 설명은 아마도 120B 모델이 주요 초점이었기 때문일 것입니다. 더 작은 모델을 만드는 가장 쉬운 방법은 모델을 조금 더 짧게 만들고(transformer 블록 수를 줄임) 전문가 수를 줄이는 것이었는데, 대부분의 파라미터가 여기에 있기 때문입니다. 그러나 120B 모델을 훈련하기 시작한 다음 무작위 가중치에서 시작하는 대신 지속적인 사전 훈련을 위해 일부 트랜스포머 블록과 전문가를 잘라낸 것은 아닌지 추측할 수 있습니다.
어쨌든 이 두 가지(Transformer 블록과 MoE 수)만 확장하는 것은 매우 드문 일이기 때문입니다. 예를 들어, 다양한 크기의 Qwen3 MoE 모델(아래 그림 17)을 보면 더 많은 측면에서 서로 비례적으로 확장되었습니다.

3.3 Attention 편향과 주의 싱크
gpt-oss와 Qwen3는 모두 그룹화된 쿼리 주의력을 사용합니다. 가장 큰 차이점은 앞서 언급한 것처럼 gpt-oss는 각 두 번째 레이어에서 슬라이딩 윈도우 주의를 통해 컨텍스트 크기를 제한한다는 점입니다.
하지만 한 가지 흥미로운 세부 사항이 눈에 띄었습니다. 아래 그림에서 볼 수 있듯이 gpt-oss는 주의력 가중치에 바이어스 단위를 사용하는 것 같습니다.

GPT-2 시대 이후로 이러한 편향 유닛이 사용되는 것을 본 적이 없으며, 일반적으로 불필요한 것으로 여겨지고 있습니다. 실제로 최근 논문을 통해 수학적으로 이 사실이 최소한 키 변환(k_proj)에 대해 성립한다는 것이 입증되었습니다. 또한 실증적 결과는 편향 유닛을 사용하든 사용하지 않든 간에 거의 차이가 없다는 것을 보여줍니다(아래 그림 19 참조).

또 다른 세부 사항으로, 그림 18의 코드 스크린샷에서 싱크(sink)의 정의가 눈에 띌 수 있습니다. 일반적인 모델에서 주의 싱크는 시퀀스의 시작 부분에 배치되어 주의력을 안정화하는 특수한 "항상 주의되는" 토큰입니다. 이는 특히 긴 컨텍스트 시나리오에서 유용합니다. 즉, 컨텍스트가 매우 길어지더라도 시퀀스 시작 부분의 이 특수한 주의 토큰은 여전히 주의되며, 전체 시퀀스에 대한 일반적으로 유용한 정보를 저장하도록 학습할 수 있습니다. (이 개념은 원래 'Efficient Streaming Language Models with Attention Sinks' 논문에서 제안된 것으로 생각합니다.)
gpt-oss 구현에서는 주의 싱크가 입력 시퀀스의 실제 토큰이 아닙니다. 대신 각 헤드에 대한 편향 로짓으로 학습되며, 주의 점수에 추가됩니다(그림 20). 목표는 위에서 언급된 주의 싱크와 동일하지만, 토큰화된 입력 데이터를 수정하지 않는 점이 다릅니다.

3.4 라이선스
마지막으로, Qwen3와 마찬가지로 gpt-oss 모델은 Apache 2.0 오픈소스 라이선스를 사용합니다. 이는 훌륭한 선택입니다(제 개인적인 오픈소스 프로젝트에도 선호하는 라이선스입니다). 이 라이선스 하에서는 모델을 다른 모델로 추출하거나 상업용 제품에 제한 없이 사용할 수 있습니다.
오픈-웨이트 vs. 오픈소스 LLM. 이 구분은 수년간 논의되어 왔지만, 이번 릴리스와 그 결과물에 대한 혼란을 피하기 위해 명확히 하는 것이 좋습니다. 일부 모델 개발자는 모델 가중치와 추론 코드만 공개합니다(예: Llama, Gemma, gpt-oss), 반면 다른 개발자(예: OLMo)는 훈련 코드, 데이터셋, 가중치를 모두 포함해 진정한 오픈소스로 공개합니다.
이 엄격한 정의에 따르면 gpt-oss는 Qwen3와 마찬가지로 오픈-웨이트 모델입니다. 왜냐하면 훈련 코드나 데이터셋은 포함하지 않지만 가중치와 추론 코드는 포함하기 때문입니다. 그러나 이 용어는 산업 전반에서 일관되게 사용되지 않습니다.
gpt-oss의 "oss"가 오픈 소스 소프트웨어를 의미한다고 가정하지만, OpenAI가 공식 발표 기사에서 gpt-oss를 명확히 오픈 웨이트 모델로 설명한 점은 긍정적으로 놀랍습니다.
기타 흥미로운 정보 4가지
이전 섹션에서는 GPT-2 이후 아키텍처가 어떻게 발전해 왔는지 설명하고 Qwen3(및 대부분의 다른 최신 모델)와의 유사점에 대해 설명했지만 아직 언급하지 않은 몇 가지 주목할 만한 추가 세부 사항이 있습니다. 이는 이전 섹션에 깔끔하게 포함되지는 않았지만 여전히 언급할 가치가 있는 사항입니다.
4.1 Training 개요
gpt-oss 모델은 최첨단 사전 교육 및 사후 교육 기법을 사용하여 훈련되었습니다 [...] (1)
[...] 완료하는 데 210만 H100시간이 필요했지만, gpt-oss-20b는 거의 10배나 적은 시간이 필요했습니다. (1)
[...] 감독된 미세 조정 단계와 고성능 컴퓨팅 RL 단계 포함 [...] (2)
대부분 영어로 된 텍스트 전용 데이터 세트로 모델을 학습시켰으며, STEM, 코딩 및 일반 지식에 중점을 두었습니다. (2)
따라서 gpt-oss 모델은 추론 모델이라는 것을 알 수 있습니다. 210만 H100 GPU 시간의 훈련 컴퓨팅은 약 5.6배 더 큰 H800 GPU 시간인 278만 8,000시간과 거의 비슷한 수준입니다.DeepSeek V3모델에 대한 교육을 받았습니다. 안타깝게도 아직 Qwen3 교육 시간에 대한 정보는 없습니다.
4.2 추론 노력
이전 섹션에서 언급된 대로, gpt-oss 모델은 추론 모델입니다. 그러나 특히 흥미로운 점은 사용자가 추론 시간 조정 기능을 통해 추론의 정도를 쉽게 제어할 수 있도록 훈련되었다는 점입니다.
구체적으로, gpt-oss 모델은 시스템 프롬프트의 일부로 "추론 노력: 낮음/중간/높음"이라는 지시를 받을 수 있으며, 이는 응답의 길이 및 정확도에 직접적인 영향을 미칩니다. 이는 그림 21에 표시되어 있습니다.

이 수준의 조정 가능성은 비용, 계산 자원, 정확도를 균형 있게 조정할 수 있기 때문에 유용합니다. 예를 들어, 작업이 단순한 경우(예: 간단한 지식 질문에 답변하거나 작은 오타를 수정하는 등)에는 확장된 추론을 생략할 수 있습니다. 이는 시간과 자원을 절약하며, 불필요하게 긴 응답이나 장황한 추론 기록을 피할 수 있습니다.
OpenAI가 강화 학습 기반 추론 훈련 전에 기본 모델을 공개하지 않은 것은 다소 아쉽습니다. Qwen3나 OLMo와 달리 기본 모델은 추론 방법 연구에 특히 유용한 출발점이기 때문입니다(이것이 제가 현재 Qwen3 Base와 작업하는 것을 선호하는 이유 중 하나입니다). 제 추측으로는 OpenAI의 결정은 연구 고려사항보다 산업 및 생산 환경에서의 사용 사례에 더 초점을 맞췄기 때문일 것입니다.
원본 Qwen3 모델에는 추론 모드를 활성화/비활성화하는 토글(토큰화기에서 enable_thinking=True/False 설정으로, <think></think> 태그를 추가하여 추론 행동을 비활성화합니다)이 있습니다. 그러나 Qwen3 팀은 최근 몇 주 동안 모델을 업데이트하고 하이브리드 모델에서 전용 Instruct/Thinking/Coder 변형으로 전환했습니다.
이 변경의 이유는 하이브리드 모드가 개별 모델에 비해 성능이 낮았기 때문입니다.
커뮤니티와 논의하고 이 문제에 대해 숙고한 끝에 하이브리드 사고 모드를 포기하기로 결정했습니다. 이제 최상의 품질을 달성하기 위해 지시하기와 사고하기 모델을 개별적으로 훈련할 것입니다.출처
4.3 MXFP4 최적화: 작지만 중요한 디테일
정량화 형식은 주로 모바일 또는 임베디드 AI와 관련된 틈새 주제였지만, 더 큰 모델을 추구하면서 상황이 바뀌었습니다. 이 경우 MXFP4 최적화를 통해 단일 GPU 장치에서 모델을 실행할 수 있습니다.
실제 모습은 다음과 같습니다.
- 대형 모델(예: 120B)은 단일 80GB H100 또는 최신 GPU에 적합합니다. 소비자용 하드웨어는 아니지만, 멀티 H100 머신보다 1-H100 머신을 임대하는 것이 훨씬 저렴합니다. 게다가 여러 대의 GPU에 모델을 분산하고 통신 오버헤드를 추가하는 것에 대해 걱정할 필요가 없습니다. AMD MI300X 카드가 첫날부터 지원된다는 점도 정말 좋습니다!
- 더 작은 20B 모델은 16GB VRAM에도 장착할 수 있지만, 주의할 점은 MXFP4를 지원하려면 RTX 50 시리즈 이상의 GPU여야 한다는 점입니다.
이 모델들은 MXFP4를 지원하지 않는 구형 하드웨어에서도 실행되므로 더 많은 RAM을 소비하게 됩니다. MXFP4 최적화가 없는 bfloat16의 모델은 48GB(gpt-oss-20b) 및 240GB(gpt-oss-120b)와 같이 더 많은 용량을 소비합니다.
그런데, 저는 ollama를 사용하여 Mac Mini에서 gpt-oss-20b 모델을 편안하게 실행할 수 있습니다. 약 13.5Gb 또는 메모리를 사용하므로 정말 합리적입니다.
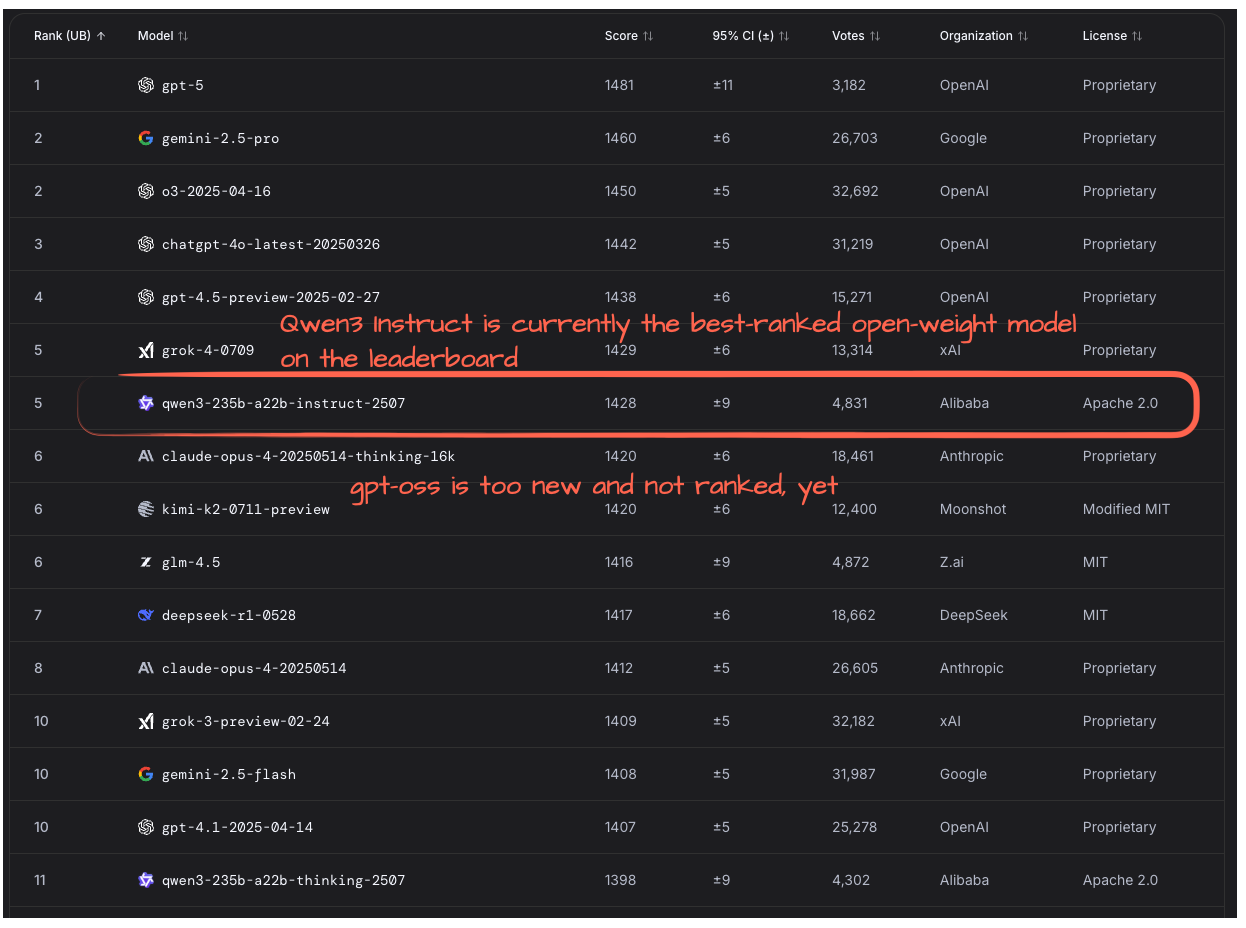
4.4 벤치마크
이 모델은 아직 독립적인 벤치마크를 하기에는 너무 새롭습니다. 확인LM 아레나 리더보드를 검색해 보니 아직 gpt-oss가 목록에 없는 것을 발견했습니다. 따라서 LM 아레나의 사용자에 따르면 현재로서는 Qwen3-Instruct가 오픈 웨이트 모델 중 가장 높은 순위를 유지하고 있습니다(그림 22).

gpt-oss 발표 포스트에서 제공하는 추론 벤치마크를 보면, gpt-oss 모델이 OpenAI의 독점 모델 및 Qwen3와 동등한 수준임을 알 수 있습니다(그림 23).

출처
- https://openai.com/ko-KR/index/gpt-oss-model-card/
- https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507
그러나 이 점은 gpt-oss-120b가 Qwen3 A235B-A22B-Thinking-2507 모델의 거의 절반 크기이며 단일 GPU에서 실행 가능하다는 점을 고려해야 합니다.
벤치마크 성능은 항상 실제 사용 환경을 반영하지는 않습니다. 지난 몇 일간의 제한된 사용 경험에서 gpt-oss는 상당히 우수한 성능을 보여주었습니다. 그럼에도 불구하고, 다른 사용자들이 지적한 것처럼 gpt-oss는 상대적으로 높은 환각 발생 경향을 보입니다(이 점은 모델 카드에서도 언급되었습니다).
이는 수학, 퍼즐, 코드와 같은 추론 작업에 집중된 훈련 방식에서 비롯된 것으로, 일부 '일반 지식 상실' 현상이 발생했을 수 있습니다. 그러나 gpt-oss가 도구 사용을 목적으로 설계되었기 때문에, 이 한계는 시간이 지나면서 덜 중요해질 수 있습니다. 오픈소스 LLM에서의 도구 통합은 아직 초기 단계에 있지만, 이 기술이 성숙해감에 따라 모델이 사실이나 지식 기반 질문에 답변할 때 외부 소스(예: 검색 엔진)를 참조하도록 하는 것이 점점 더 일반화될 것으로 예상됩니다.
만약 그런 상황이 발생한다면, 기억력보다 추론 능력을 우선시하는 것이 합리적일 수 있습니다. 이는 학교에서의 인간 학습(또는 삶 전반)과 유사하며, 문제 해결 능력이 사실 암기보다 더 중요하게 여겨지는 경우와 같습니다.
5. gpt-oss 및 GPT-5
OpenAI는 바쁜 한 주를 보냈고, gpt-oss 직후 오랫동안 기다려온 GPT-5 모델을 출시했습니다. GPT-5 출시는 흥미로웠습니다. 여기서 한 가지 말씀드리고 싶은 것이 있다면, 오픈 소스 모델이 벤치마크 성능 측면에서 최고의 제품과 비교했을 때 얼마나 뛰어난지 정말 놀랐다는 것입니다(그림 24).

결론적으로, 일부 사람들이 출시를 과대평가했다고 비판했지만, 최고의 독점 모델과 큰 차이가 없는 강력한 오픈 웨이트 모델 세트가 출시된 점은 기쁘게 생각합니다. 물론 벤치마크는 실제 사용 환경을 정확히 반영하지 않을 수 있으며, 현재까지의 제한된 사용 사례만으로는 아직 판단하기 이르지만, 오픈 웨이트 및 로컬(또는 사설 호스팅) 모델을 선호하는 사람들에게는 좋은 시기라고 생각합니다.
'AI-ML > LLM' 카테고리의 다른 글
| GPT-OSS 시각화 (0) | 2025.08.21 |
|---|---|
| LLM에서 Self-Attention, Multi-Head Attention, Causal-Attention, 및 Cross-Attention의 이해와 Code 해석 (6) | 2025.08.11 |
| 추론 능력(Reasoning) 이해를 위한 대규모 언어 모델(LLMs) (3) | 2025.07.22 |
| 대규모 언어 모델(LLM) 아키텍처 비교 (2) | 2025.07.22 |
| Amazon Sagemaker JupyterLab Kernel 설정하기 (0) | 2025.02.21 |



{kind=link}
{kind=link}