https://www.arxiv.org/abs/2510.02330
EntropyLong: Effective Long-Context Training via Predictive Uncertainty
Training long-context language models to capture long-range dependencies requires specialized data construction. Current approaches, such as generic text concatenation or heuristic-based variants, frequently fail to guarantee genuine long-range dependencie
arxiv.org
EntropyLong은 예측 불확실성을 활용하여 정보 부족을 식별하고 추가된 컨텍스트의 유용성을 경험적으로 검증함으로써 대규모 언어 모델(LLM)을 위한 고품질 장문 컨텍스트 훈련 데이터를 생성하는 새로운 프레임워크를 제안합니다. 이 방법론으로 훈련된 모델들은 평균 RULER 점수 87.37점과 LongBench-v2 점수 27.60점을 달성하여, 향상된 장문 컨텍스트 이해, ‘중간에 정보 유실’ 문제 완화, 그리고 128K 컨텍스트 길이에서 Needle-in-a-Haystack 작업에 대한 100% 정확도를 입증했습니다.
목차
개요
장문 맥락 이해는 대규모 언어 모델(LLM) 발전에 있어 가장 중요한 과제 중 하나입니다. 아키텍처 혁신을 통해 이론적으로는 맥락 창이 수백만 개의 토큰으로 확장되었지만, 모델들은 장거리 추론을 진정으로 필요로 하는 고품질 훈련 데이터 부족이라는 근본적인 병목 현상 때문에 이러한 확장된 기능을 효과적으로 활용하는 데 어려움을 겪는 경우가 많습니다. EntropyLong은 경험적으로 검증된 장거리 종속성을 포함하는 훈련 데이터를 구축하기 위한 원칙적인 정보 이론적 접근 방식을 도입하여 이 문제를 해결합니다.

그림 1: 검증된 종속성을 가진 장문 맥락 훈련 데이터를 구축하기 위한 4단계 EntropyLong 파이프라인. 이 방법은 고엔트로피 위치를 식별하고, 관련 맥락을 검색하며, 엔트로피 감소를 통해 유용성을 검증하고, 이를 루트 문서와 전략적으로 연결합니다.
문제 진술 및 동기
장문 맥락 훈련 데이터를 생성하는 현재 접근 방식은 중요한 한계에 직면해 있습니다. 유용한 장거리 종속성을 구성하는 요소에 대한 휴리스틱한 가정에 의존한다는 점입니다. 기존 방법은 크게 세 가지 유형으로 분류할 수 있습니다.
- 일반 텍스트 연결: 단순히 관련 없는 문서를 이어 붙이는 방식으로, 의미 있는 종속성을 설정하지 못합니다.
- 휴리스틱 기반 합성: Quest(일관성 중심) 및 NExtLong(판별 중심)과 같이 주제 유사성 또는 교차 전략을 사용하는 방법입니다.
- 제한적인 검증 접근 방식: RE³SYN과 같이 문서 수준 검증을 위해 프록시 모델을 사용하는 최근 연구입니다.
이러한 접근 방식들은 대상 모델의 관점에서 추가된 맥락이 진정한 정보 이득을 제공하는지 직접 측정하지 않고 "좋은" 장문 맥락 예시를 구성하는 요소를 근본적으로 가정합니다. 이는 의미 있는 장거리 이해보다는 잘못된 상관관계로 이어질 수 있습니다.
EntropyLong 방법론
EntropyLong은 예측 불확실성을 정보 부족에 대한 직접적인 신호로 사용하여 패러다임의 전환을 가져옵니다. 핵심 통찰은 어떤 토큰 위치에서 모델의 예측 엔트로피가 자신감 있는 예측을 위한 충분한 맥락이 부족한 곳을 나타낸다는 것입니다. 이 방법은 멀리 떨어진 맥락을 도입하면 이 엔트로피가 감소하여 진정한 정보 이득을 보장한다는 것을 경험적으로 검증합니다.
이론적 기초
이 접근 방식은 예측 엔트로피가 불확실성을 정량화하는 정보 이론에 기반을 두고 있습니다.
H_θ(x_t|x_{<t}) = -\sum_{x} P_θ(x_t = x|x_{<t}) \log P_θ(x_t = x|x_{<t})
$$
핵심 원칙은 *맥락 정보 이득(Contextual Information Gain)*을 최대화하는 것으로, 다음과 같이 정의됩니다.
ΔI_t(C, D) = \frac{H_θ(x_t|D) - H_θ(x_t|C, D)}{H_θ(x_t|D)}
$$
여기서 $C$는 후보 맥락이고 $D$는 루트 문서이며, 효과적인 맥락은 임계값 $ε$에 대해 $ΔI_t > ε$을 만족해야 합니다.
4단계 파이프라인
1단계: 적응형 고엔트로피 위치 선택 EntropyLong은 고정된 임계값을 사용하는 대신 적응형 접근 방식을 사용합니다.
τ_H = μ_H + α \cdot σ_H
$$
여기서 $μ_H$와 $σ_H$는 각 문서 내 엔트로피의 평균과 표준 편차이며, $α$는 선택성을 제어합니다(일반적으로 $α = 2.0$). 이는 해당 문서 맥락 내에서 모델이 진정으로 불확실한 토큰을 식별합니다.
2단계: 정보 이론적 맥락 검색 각 고엔트로피 위치에 대해 주변 맥락(일반적으로 이전 16단어 및 이후 16단어)을 사용하여 쿼리를 구성합니다. 문장 변환기를 사용한 밀집 검색은 대규모 코퍼스에서 가장 의미론적으로 유사한 상위 K개 문서를 식별합니다.
3단계: 엔트로피 감소 검증 이 중요한 단계는 EntropyLong을 이전 방법과 구별합니다. 각 검색된 맥락은 원본 문서 앞에 추가되며, 모델은 고엔트로피 위치에서 엔트로피를 다시 평가합니다. 맥락은 엔트로피를 최소 임계값 $ε$(일반적으로 0.4) 이상으로 감소시키는 경우에만 유지되어 측정 가능한 정보 이득을 보장합니다.
4단계: 전략적 연결 검증된 컨텍스트는 루트 문서와 연결됩니다. 두 가지 전략이 테스트되었습니다:
- 셔플 전략(Shuffle Strategy): 컨텍스트의 무작위 순서 지정 (더 효과적인 것으로 나타남)
- 순차 전략(Sequence Strategy): 원래 토큰 위치 기반 순서 지정
실험 결과 및 검증
저자들은 128K 길이 시퀀스의 40억 토큰 훈련 코퍼스를 구축하고 이 데이터로 훈련된 모델들을 여러 벤치마크에서 평가했습니다.
RULER 벤치마크 성능
EntropyLong은 다양한 장문 컨텍스트 기능을 테스트하는 RULER 벤치마크에서 상당한 개선을 달성했습니다:
- 전체 평균 점수: 87.37 (Quest: 80.53, NExtLong: 85.22 대비)
- 128K 컨텍스트 길이: 81.26 (Quest: 60.11, NExtLong: 77.99 대비)
가장 긴 컨텍스트 길이에서 상당한 개선은 매우 먼 정보를 활용하는 우수한 능력을 보여줍니다.
명령어 미세 조정 결과
UltraChat에서 지도 미세 조정을 거친 후에도 모델들은 LongBench-v2에서 이점을 유지했습니다:
- 전체 점수: 27.60 (Quest: 22.30, NExtLong: 24.10 대비)
- "긴" 작업: 31.50 (최고 기준선 대비 8.40점 향상)
어텐션 패턴 분석
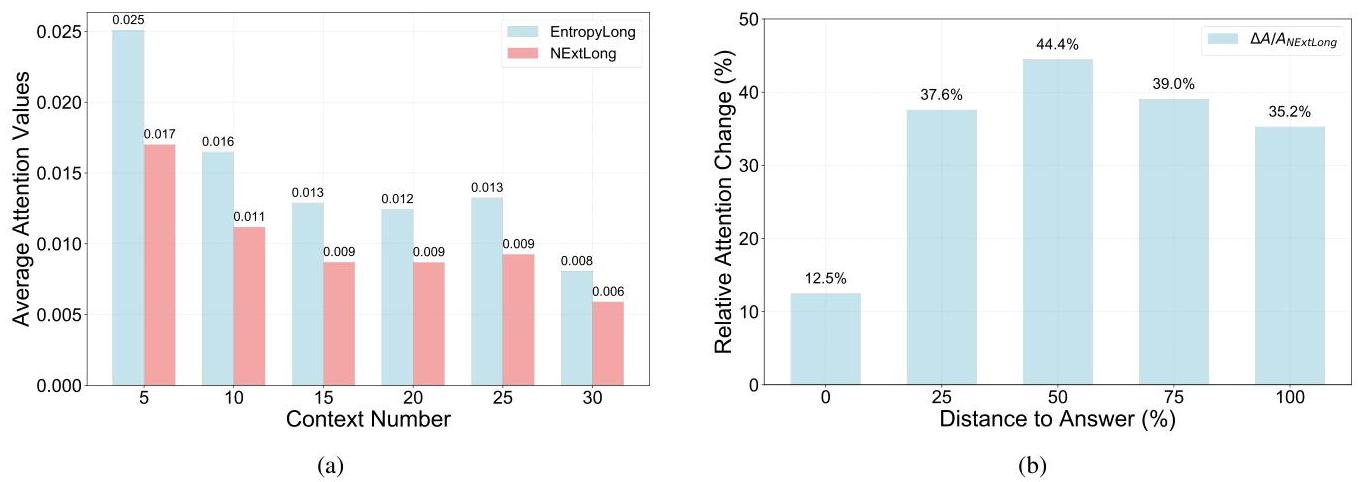
그림 2: (a) EntropyLong은 다양한 컨텍스트 길이에서 정답에 일관적으로 더 높은 어텐션을 할당합니다. (b) 상대적 어텐션 개선은 "중간에 정보가 사라지는(lost-in-the-middle)" 현상을 크게 완화하며, 정답이 중간 위치에 있을 때 최대 44.4%의 개선을 보여줍니다.
어텐션 분석은 두 가지 주요 개선점을 보여줍니다:
- 일관된 어텐션 할당: EntropyLong은 컨텍스트 길이에 관계없이 관련 정보에 더 높은 어텐션을 유지합니다.
- "중간에 정보가 사라지는" 현상 완화: 대상 정보가 중간 위치에 있을 때 어텐션에서 최대 44.4%의 상대적 개선을 보입니다.
건초 더미 속 바늘(Needle-in-a-Haystack) 성능
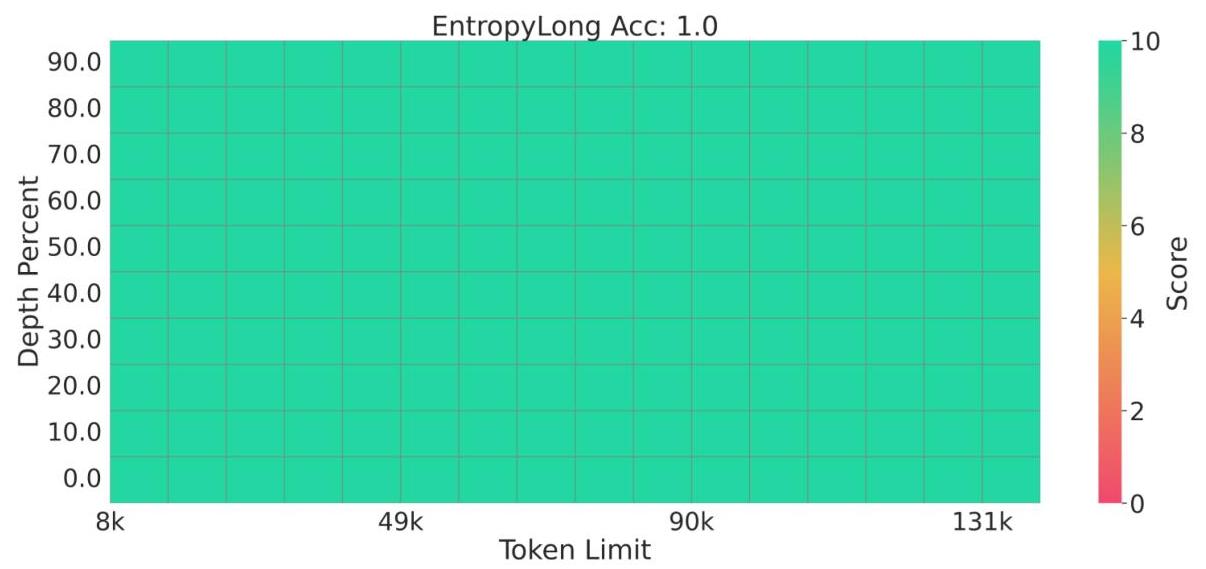
그림 3: EntropyLong은 건초 더미 속 바늘 작업에서 128K 토큰까지의 모든 위치와 컨텍스트 길이에서 100%의 완벽한 정확도를 달성하여 견고한 정보 검색 기능을 보여줍니다.
EntropyLong은 건초 더미 속 바늘 테스트에서 모든 위치와 컨텍스트 길이(최대 128K 토큰)에서 100% 정확도를 달성하여 긴 컨텍스트 내에서 대상 정보를 찾는 데 있어 탁월한 정밀도를 입증했습니다.
제거 연구 및 핵심 검증
포괄적인 제거 연구는 핵심 구성 요소의 필요성을 검증했습니다:
검증의 필요성: 엔트로피 감소 검증(EntropyLong-NoVerify)을 제거하자 RULER 성능이 87.37에서 85.82로 감소하여, 경험적 필터링의 중요성을 확인했습니다.
임계값 최적화:
- 높은 엔트로피 선택 임계값 $α = 2.0$이 선택된 위치의 양과 질의 균형을 맞추는 데 최적임을 입증했습니다.
- 엔트로피 감소 임계값 $ε = 0.4$가 최고의 결과를 달성하여 충분한 고품질 종속성을 보장했습니다.
연결 전략: 컨텍스트의 무작위 셔플링이 순차적 순서 지정보다 우수했으며, 이는 위치 기반 학습보다는 내용 기반 학습의 중요성을 시사합니다.
중요성 및 영향
EntropyLong은 다음과 같은 몇 가지 주요 기여를 통해 장문 컨텍스트 LLM 훈련에서 근본적인 발전을 이룹니다:
- 패러다임 전환: 발견적 기반에서 모델-인-더-루프(model-in-the-loop) 검증을 통한 원칙적, 정보 이론적 데이터 구축으로의 전환
- 정보 이득 보장: 훈련 데이터의 모든 장거리 종속성은 측정 가능한 정보 이득을 나타내어 거짓 상관관계를 제거합니다.
- 우수한 성능: 특히 매우 긴 컨텍스트 길이에서 어려운 벤치마크에서 상당한 개선을 이룹니다.
- 커뮤니티 자원: 128K 길이 훈련 코퍼스의 오픈 소싱은 미래 연구를 위한 귀중한 자원을 제공합니다.
- 광범위한 적용 가능성: 불확실성 기반 접근 방식은 미세 조정 데이터 선택 및 능동 학습을 포함한 다른 데이터 큐레이션 시나리오로 확장될 수 있습니다.
이 방법론은 LLM 개발의 중요한 병목 현상을 해결하고 모델 중심 데이터 큐레이션에서 미래의 발전을 촉진할 수 있는 강력한 프레임워크를 제공합니다. EntropyLong은 훈련 데이터에 가정된 상관 관계가 아닌 검증된 기능적 종속성을 포함하도록 보장함으로써, 광범위한 문서 분석 및 추론이 필요한 산업 전반에 걸쳐 중요한 의미를 가지는 더욱 신뢰할 수 있고 유능한 장문 맥락 언어 모델 개발에 기여합니다.
'AI-ML > LLM' 카테고리의 다른 글
| LLM은 왜 환각((Hallucinate)) 증상에 빠질까? (0) | 2025.11.04 |
|---|---|
| 언어 모델은 단사적이며 따라서 가역적이다 (1) | 2025.11.04 |
| 논문 요약해서 읽어보기(feat. LLM) (0) | 2025.10.11 |
| LLM 평가의 4가지 주요 접근법 이해하기 (0) | 2025.10.06 |
| 논문 읽어보기 - Learning to Reason as Action Abstractions with Scalable Mid-Training RL (0) | 2025.10.05 |
